搜索到
4
篇与
的结果
-
 高性价比、便宜的 VPS/云服务器推荐,2025/8月更新,开设MC服务器,建站均可! 一般服务器的数值1C2G5M指的是:1核CPU,2G内存,5M带宽提醒一下:如果你是新用户有优惠,能买多长时间就买多长时间,因为优惠价的服务器时间到后续费很贵的,而且新用户优惠只能买一次,所以尽量买长时间点划算。如果需要的配置比较高建议先买高配置的,因为购买后不是新用户无法再以优惠价购买其他了。目前 阿里云、腾讯云、华为云、UCloud 等这些大厂都是按主体(身份证)算新用户的,如果你同主体下已经有其他账号消费过了就不算新用户了,没法享受新用户优惠。目前国内排名前三的云服务厂商分别是阿里云、腾讯云、华为云。下面部分商家通过我链接注册的有额外优惠。阿里云:https://www.aliyun.com/minisite/goods?userCode=3jhao3pu腾讯云:https://curl.qcloud.com/2dJY7V7z雨云(性价比之选):https://www.rainyun.com/NzYxMjMy_国内服务器腾讯云,2核4G5M,188元/年(约15.67元/月),900元/3年(约25元/月);4C8G12M,575元/年(约47.92元/月);轻量 2C1G 200M不限流量,40元/月。Ucloud :香港轻量 1C2G 30M,93元/年(约7.75元/月);境内云主机 1C2G,506元/年(约42元/月)。天翼云: 4核8G,989元/年(约82.4元/月);。华为云: 2核4G2M,99元/年(约8.3元/月);4C8G6M,498元/年(约41.5元/月);8C16G10M,3549元/年(约295.7元/月) 。腾讯云学生机,2C2G4M,112元/年;4C8G12M,646元/年。阿里云小站,2核2G 200M,68元/年。雨云:湖北 100G高防,8C8G 20M,96元/月;香港四区,2C2G 50M,33元/月。 9950X高防,4C8G 15M,200元/月 。14900K高防,4C8G 15M,176元/月。宁波 8272CL,4核8G 300M,98元/月。糖糕云:13900K,4C16G10M,409元/月;5800X,4C16G10M,309元/月;E5-2666V3,4C16G10M,80元/月。野草云:香港BGP,1C2G 100M,138元/年(约11.5元/月)。北少云:湖北 7950X 500G高防,4C10G 15M,145元/月;河南8272CL,8C30G 20M,98元/月。AkileCloud:香港BGP,1C1G 1000M,24.99元/月;台湾,1C2G 1000M,24.99元/月;均为DNS解锁流媒体和IPv4/v6双栈网络。国外服务器搬瓦工,2C1G 1000M,49.99美元/年(约4.2美元/月),CN2线路,支持换IP。雨云:美国洛杉矶,2C2G 100M,18.9元/月 。极光KVM,洛杉矶1C1G 1000M,39.8元/月;香港1C1G 20M,29.66元/月。CloudCone,1C1G 1000M,3.71美元/月。DigitalOcean,1C1G,5美元/月,按小时计费,可以随时删服,通过我的链接注册充值25美元送100美元余额。FranTech,1C1G 1000M(锐龙3900X),3.5美元/月,无限流量,有DDoS防御;中国特别版 1C1G1000M 无限流量,解锁流媒体。莱卡云:美国9929,2C1G 20M,22.4元/月;韩国双ISP住宅IP,1C1G 100M,54元/月AkileCloud:日本 EPYC7002 三网优化,1C1G 1000M,37.35元/月;美国 7950X 三网直连,1C1G 1000M,37.49元/月;均为DNS解锁流媒体和IPv4/v6双栈网络。腾讯云:韩国轻量,2C1G 200M不限流量,35元/月。阿里云:泰国轻量,2C1G 200M不限流量,34元/月。
高性价比、便宜的 VPS/云服务器推荐,2025/8月更新,开设MC服务器,建站均可! 一般服务器的数值1C2G5M指的是:1核CPU,2G内存,5M带宽提醒一下:如果你是新用户有优惠,能买多长时间就买多长时间,因为优惠价的服务器时间到后续费很贵的,而且新用户优惠只能买一次,所以尽量买长时间点划算。如果需要的配置比较高建议先买高配置的,因为购买后不是新用户无法再以优惠价购买其他了。目前 阿里云、腾讯云、华为云、UCloud 等这些大厂都是按主体(身份证)算新用户的,如果你同主体下已经有其他账号消费过了就不算新用户了,没法享受新用户优惠。目前国内排名前三的云服务厂商分别是阿里云、腾讯云、华为云。下面部分商家通过我链接注册的有额外优惠。阿里云:https://www.aliyun.com/minisite/goods?userCode=3jhao3pu腾讯云:https://curl.qcloud.com/2dJY7V7z雨云(性价比之选):https://www.rainyun.com/NzYxMjMy_国内服务器腾讯云,2核4G5M,188元/年(约15.67元/月),900元/3年(约25元/月);4C8G12M,575元/年(约47.92元/月);轻量 2C1G 200M不限流量,40元/月。Ucloud :香港轻量 1C2G 30M,93元/年(约7.75元/月);境内云主机 1C2G,506元/年(约42元/月)。天翼云: 4核8G,989元/年(约82.4元/月);。华为云: 2核4G2M,99元/年(约8.3元/月);4C8G6M,498元/年(约41.5元/月);8C16G10M,3549元/年(约295.7元/月) 。腾讯云学生机,2C2G4M,112元/年;4C8G12M,646元/年。阿里云小站,2核2G 200M,68元/年。雨云:湖北 100G高防,8C8G 20M,96元/月;香港四区,2C2G 50M,33元/月。 9950X高防,4C8G 15M,200元/月 。14900K高防,4C8G 15M,176元/月。宁波 8272CL,4核8G 300M,98元/月。糖糕云:13900K,4C16G10M,409元/月;5800X,4C16G10M,309元/月;E5-2666V3,4C16G10M,80元/月。野草云:香港BGP,1C2G 100M,138元/年(约11.5元/月)。北少云:湖北 7950X 500G高防,4C10G 15M,145元/月;河南8272CL,8C30G 20M,98元/月。AkileCloud:香港BGP,1C1G 1000M,24.99元/月;台湾,1C2G 1000M,24.99元/月;均为DNS解锁流媒体和IPv4/v6双栈网络。国外服务器搬瓦工,2C1G 1000M,49.99美元/年(约4.2美元/月),CN2线路,支持换IP。雨云:美国洛杉矶,2C2G 100M,18.9元/月 。极光KVM,洛杉矶1C1G 1000M,39.8元/月;香港1C1G 20M,29.66元/月。CloudCone,1C1G 1000M,3.71美元/月。DigitalOcean,1C1G,5美元/月,按小时计费,可以随时删服,通过我的链接注册充值25美元送100美元余额。FranTech,1C1G 1000M(锐龙3900X),3.5美元/月,无限流量,有DDoS防御;中国特别版 1C1G1000M 无限流量,解锁流媒体。莱卡云:美国9929,2C1G 20M,22.4元/月;韩国双ISP住宅IP,1C1G 100M,54元/月AkileCloud:日本 EPYC7002 三网优化,1C1G 1000M,37.35元/月;美国 7950X 三网直连,1C1G 1000M,37.49元/月;均为DNS解锁流媒体和IPv4/v6双栈网络。腾讯云:韩国轻量,2C1G 200M不限流量,35元/月。阿里云:泰国轻量,2C1G 200M不限流量,34元/月。 -
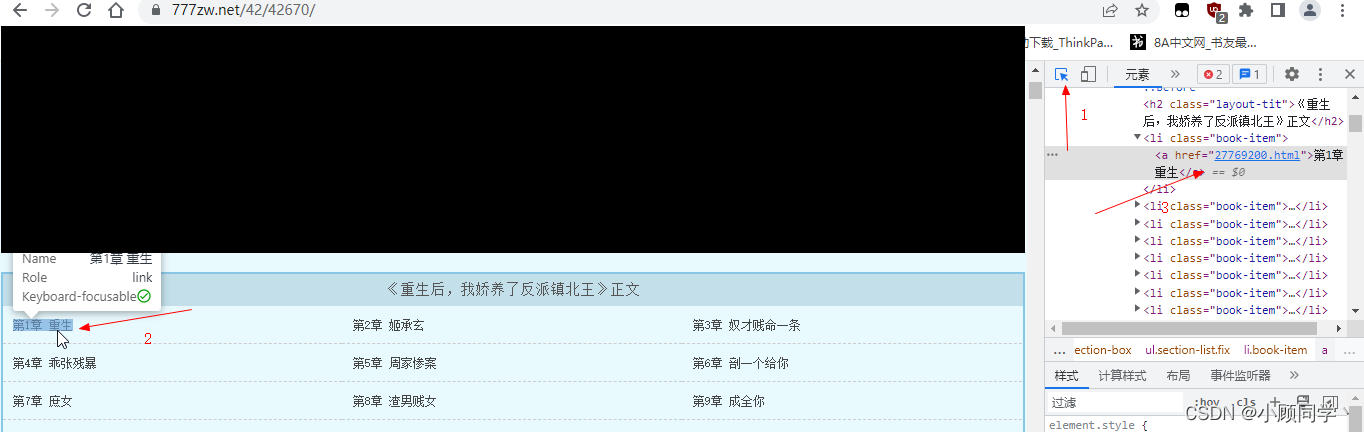
Python网页爬取小说 一、思路找到想看的小说的网站地址→爬取小说所有章节的网站地址→爬取每章小说的标题和内容→把内容保存到TXT文件二、具体步骤 1.找到小说网站 百度上有很多小说网站但是有些网站有反爬需要注意。2.爬取小说所有章节的网站地址 首先用浏览器打开小说网站,按F12我们看到章节链接在href里面,找到它的上一级鼠标移动到上一级标签,左边章节全部高亮,表示这个标签里包含了所有章节的链接,所以我们只要提去这个标签里的所有href 就可以获得所有的章节的网站地址。右键这个标签,复制,选择复制完整的xpath如下:/html/body/div[3]/div[2]/div/div/ul因为章节网站在href里所以加上//@href:/html/body/div[3]/div[2]/div/div/ul//@href然后我们就可以开始写代码了需要用到两个库:#pip install requests,pip install lxml import requests from lxml import etree开始解析网站import requests from lxml import etree url = "https://www.777zw.net/42/42670/" re= requests.get(url)#访问小说网站 re.encoding="utf-8"#改为utf-8格式,不然可能读取到的是乱码 selector=etree.HTML(re.text)#解析网站,变成HTML格式 urs=selector.xpath("/html/body/div[3]/div[2]/div/div/ul//@href") #利用Xpath,读取HTML里的信息,从而获取所以章节的链接 urs就包含了所以的章节链接地址。打印一下:['27769200.html', '27769202.html', '27769204.html', '27769206.html', '27769207.html'。。。。。 '31256765.html', '31256766.html']爬取到的网站是不全的,我们需要在前面加上https://www.777zw.net/42/42670/ 就是url for i in urs: urls1=url+i re1 = requests.get(urls1)#re1章节页面 re1.encoding = "utf-8" selector1 = etree.HTML(re1.text)这样我们就爬取到了每个章节网站。3.爬取每个章节的内容 我们先进入第一章小说的网页,发现内容里包含了章节名称我们就不用提取章节名字了,爬取内容就可以使用F12 得到内容的xpath地址/html/body/div[4]/div/div/div[2]/div[2]需要得到里面的内容就是/html/body/div[4]/div/div/div[2]/div[2]//text()//text()是得到该节点下所有的文本,/text()是得到当前节点的文本内容=selector1.xpath("/html/body/div[4]/div/div/div[2]/div[2]//text()") neir = "" for x in 内容: neir = neir + str(x) + "\n"这样就在每句话后面加了一个换行符。 with open("重生后,我娇养了反派镇北王.txt","a",encoding="utf-8") as f: f.write(neir) 最后写入txt就可以了with open("打开一个txt,没有就创建一个",a是追加写入,utf-8是写入文件格式) as f是该txt文件简称。完整代码:import requests from lxml import etree url = "https://www.777zw.net/42/42670/" re= requests.get(url) re.encoding="utf-8"#re书名页 selector=etree.HTML(re.text)#分析网站,变成HTML格式 urs=selector.xpath("/html/body/div[3]/div[2]/div/div/ul//@href")#获取所以章节的链接 for i in urs: urls1=url+i re1 = requests.get(urls1)#re1章节页面 re1.encoding = "utf-8" selector1 = etree.HTML(re1.text) 内容=selector1.xpath("/html/body/div[4]/div/div/div[2]/div[2]//text()") neir = "" for x in 内容: neir = neir + str(x) + "\n" with open("重生后,我娇养了反派镇北王.txt","a",encoding="utf-8") as f: f.write(neir)优化后的代码: #pip install requests,pip install lxml import requests from lxml import etree url = "https://www.777zw.net/42/42670/" re= requests.get(url) re.encoding="utf-8"#re书名页 selector=etree.HTML(re.text)#分析网站,变成HTML格式 urs=selector.xpath("/html/body/div[3]/div[2]/div/div/ul//@href")#获取所以章节的链接 shum=selector.xpath("/html/body/div[3]/div[1]/div/div/div[2]/div[1]/h1/text()")[0]#获取书名,因为得到是列表所以要【0】 Y=0 print(f"{shum}开始下载,共{len(urs)}章") for i in urs: urls1=url+i re1 = requests.get(urls1)#re1章节页面 re1.encoding = "utf-8" selector1 = etree.HTML(re1.text) 内容=selector1.xpath("/html/body/div[4]/div/div/div[2]/div[2]//text()") neir="" for x in 内容: neir=neir+str(x)+"\n" with open(shum+".txt","a",encoding="utf-8") as f: f.write(neir) Y = Y + 1 print(f"第{Y}章下载完成") if Y==10:#下载第10章后退出程序 exit()
-
-